The Big LLM Architecture Comparison
Subtitle: From DeepSeek V3 to Mistral 3 Large: A Look At Modern LLM Architecture Design
Date: FEB 5, 2025 (Last updated: Dec 18, 2025)
URL: https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
Likes: 1,723
Image Count: 60
Images
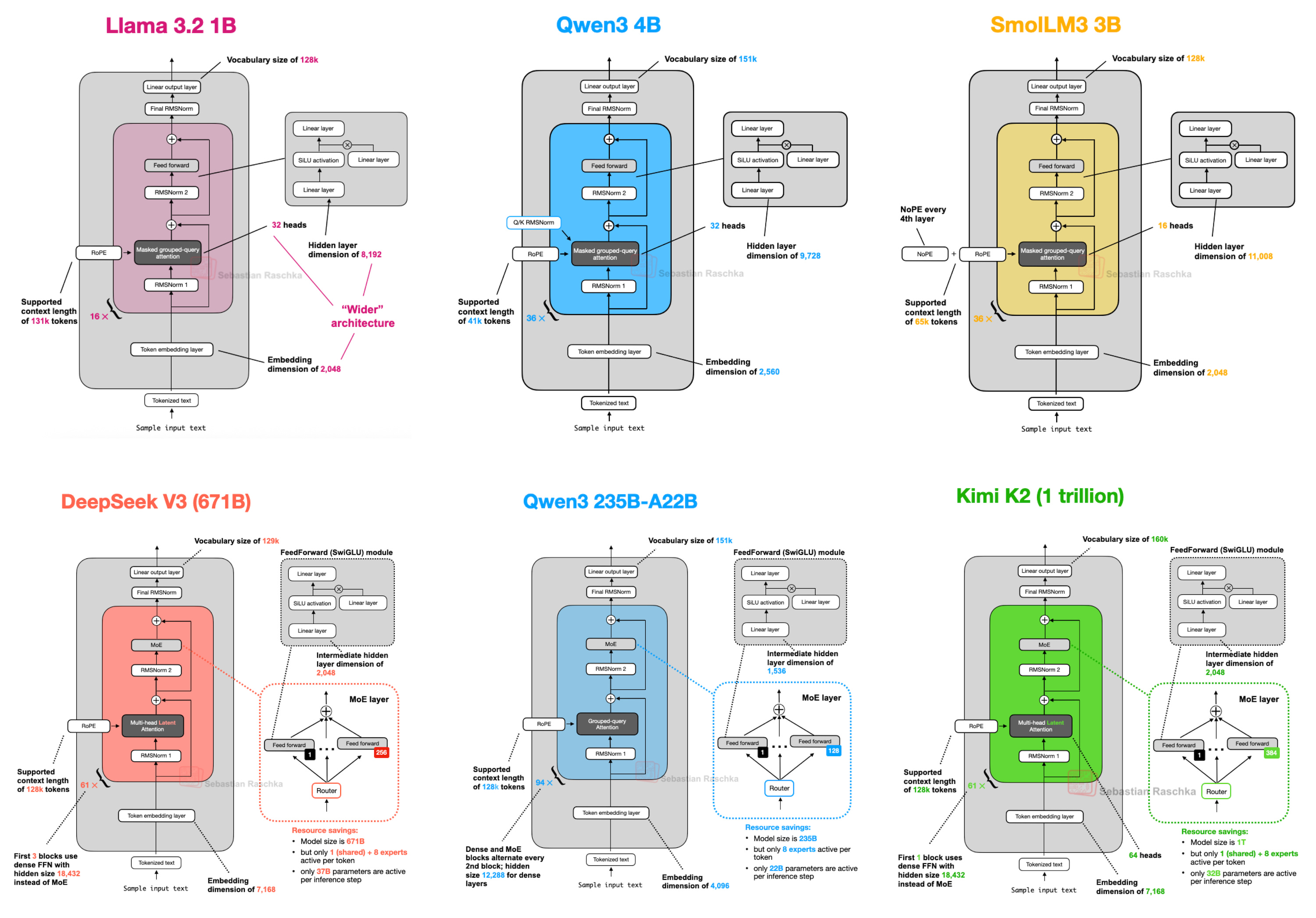
Figure 1 - Caption: Figure 1: A subset of the architectures covered in this article.
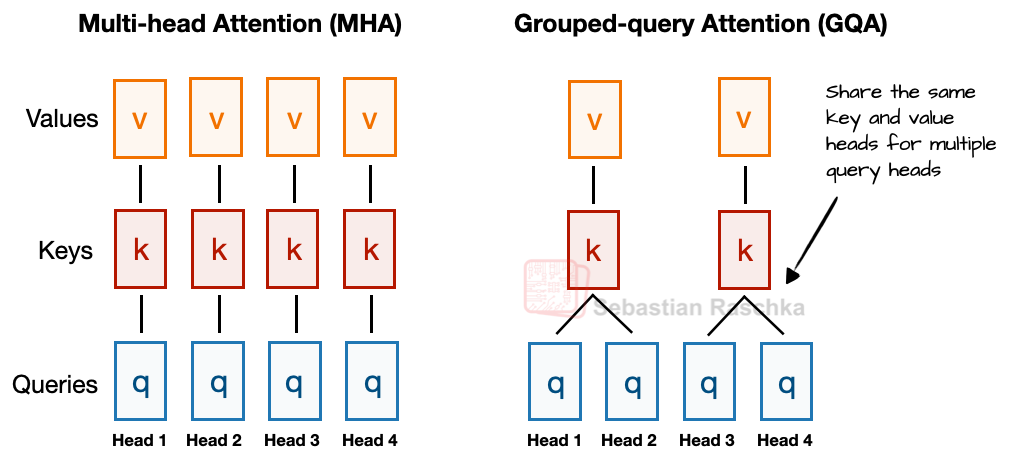
Figure 2 - Caption: Figure 2: A comparison between MHA and GQA. Here, the group size is 2, where a key and value pair is shared among 2 queries.
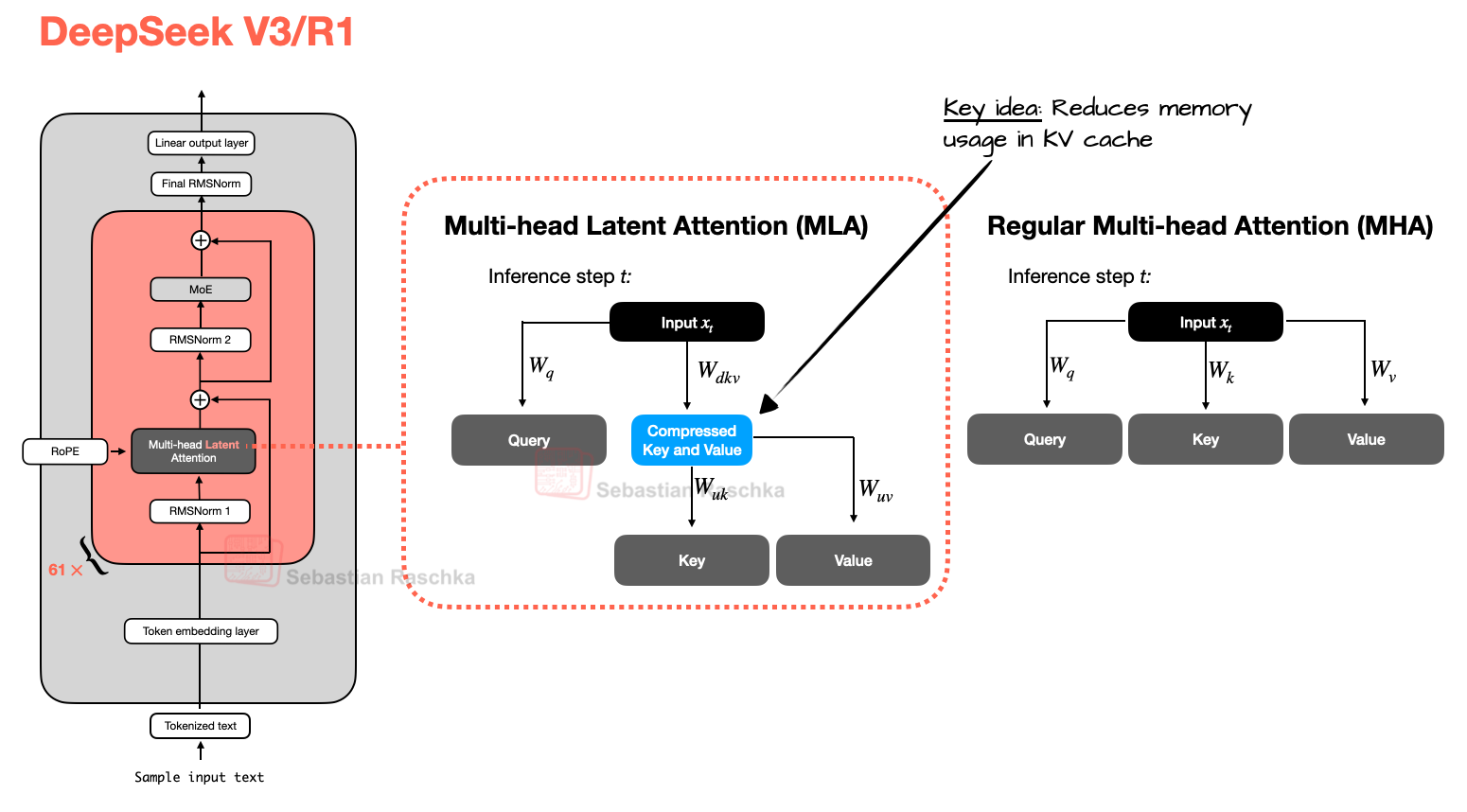
Figure 3 - Caption: Figure 3: Comparison between MLA (used in DeepSeek V3 and R1) and regular MHA.
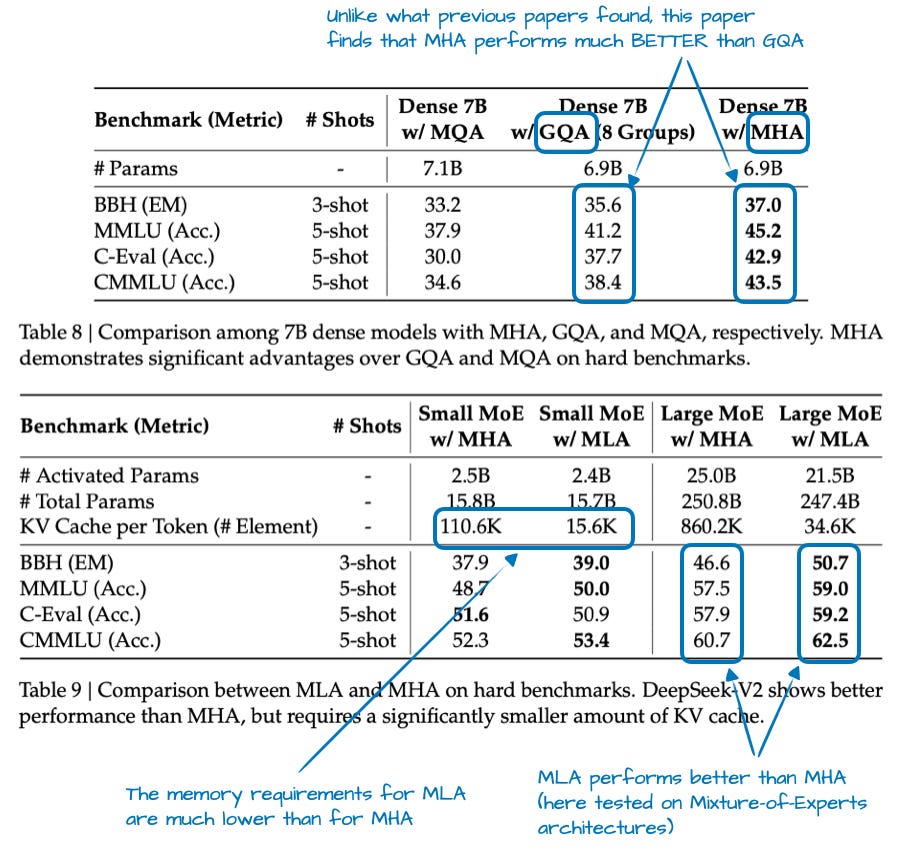
Figure 4 - Caption: Figure 4: Annotated tables from the DeepSeek-V2 paper, https://arxiv.org/abs/2405.04434
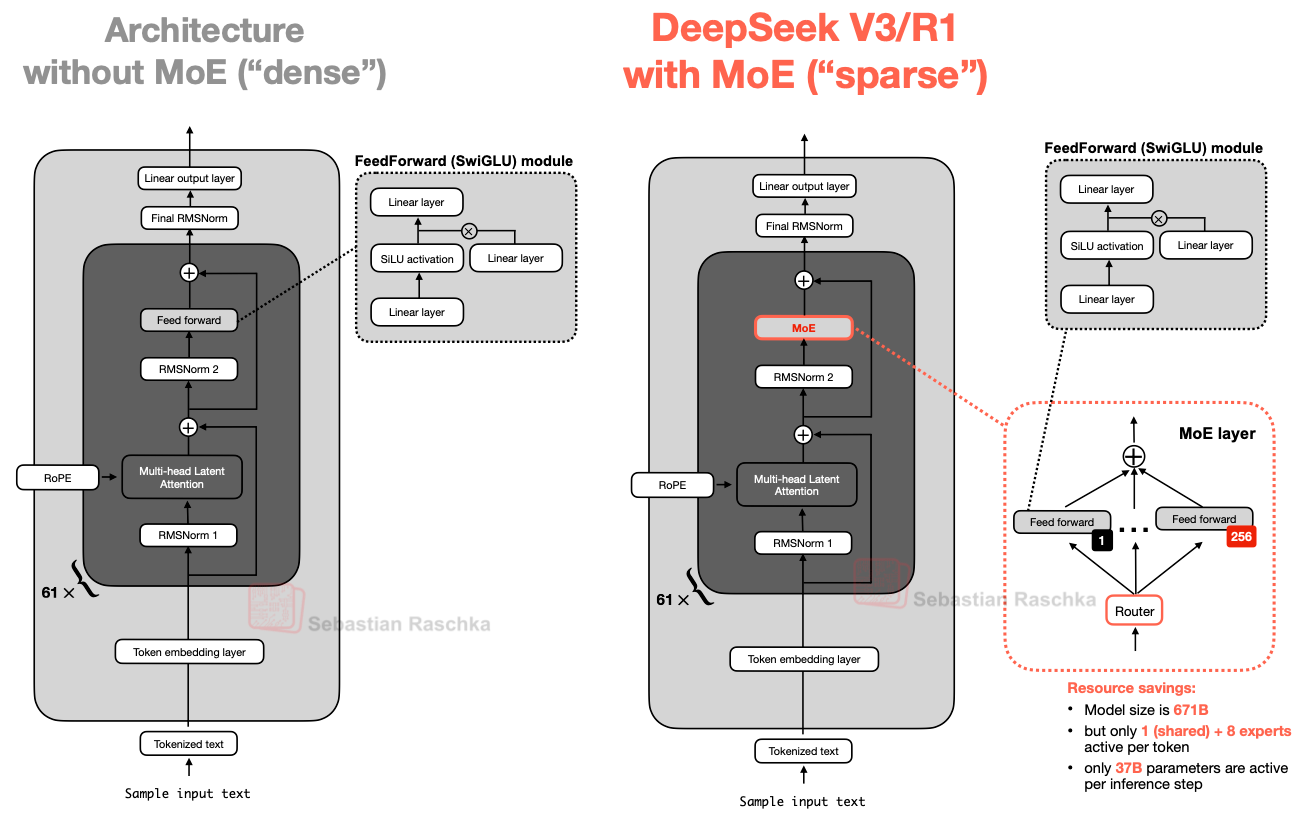
Figure 5 - Caption: Figure 5: An illustration of the Mixture-of-Experts (MoE) module in DeepSeek V3/R1 (right) compared to an LLM with a standard FeedForward block (left).
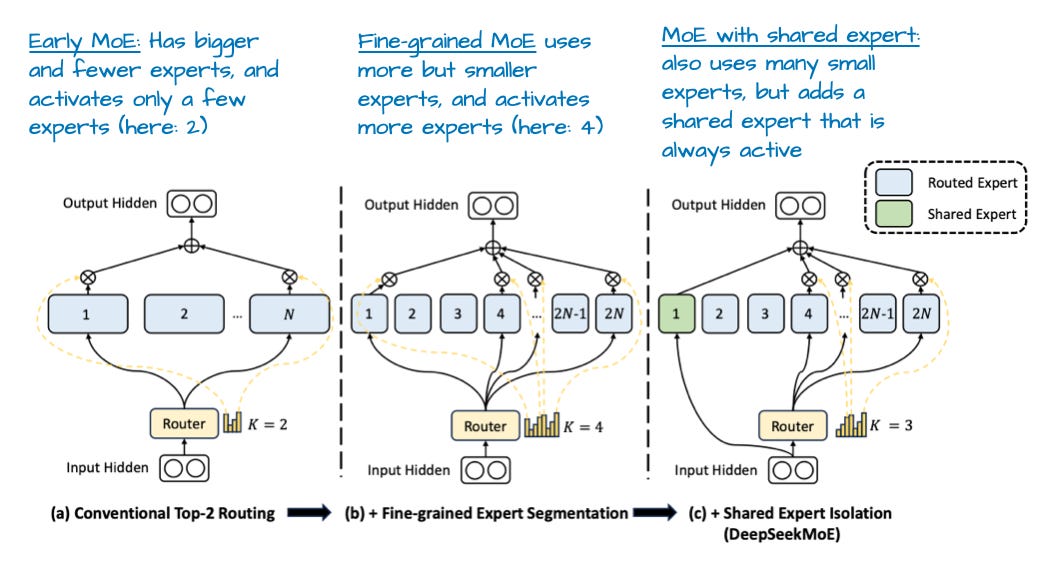
Figure 6 - Caption: Figure 6: An annotated figure from “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models”
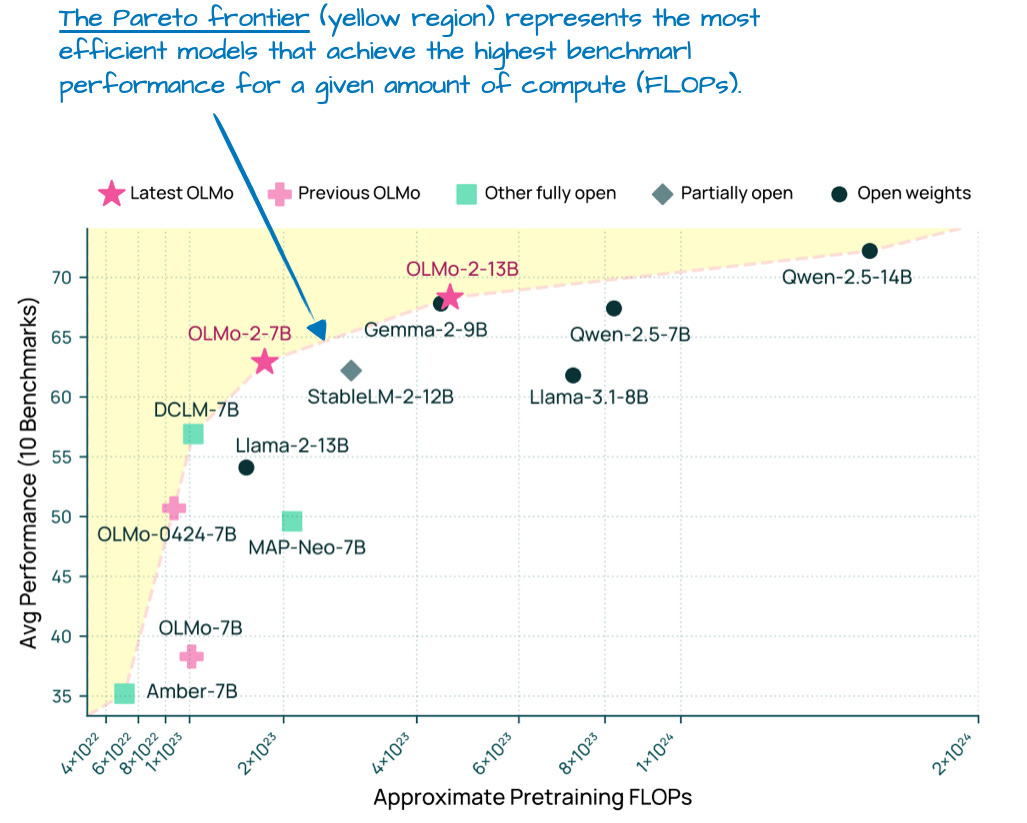
Figure 7 - Caption: Figure 7: Modeling benchmark performance (higher is better) vs pre-training cost (FLOPs; lower is better) for different LLMs.
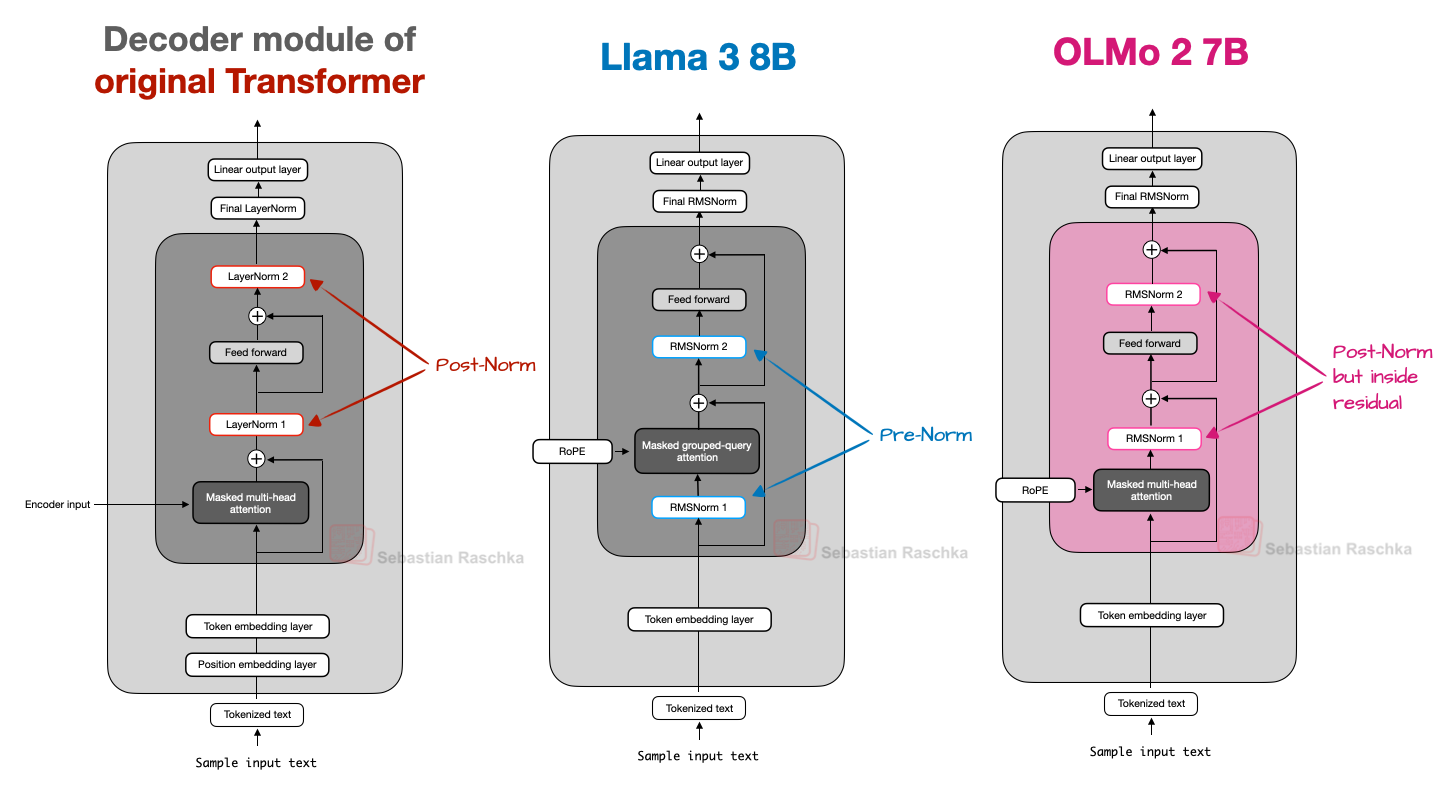
Figure 8 - Caption: Figure 8: A comparison of Post-Norm, Pre-Norm, and OLMo 2’s flavor of Post-Norm.
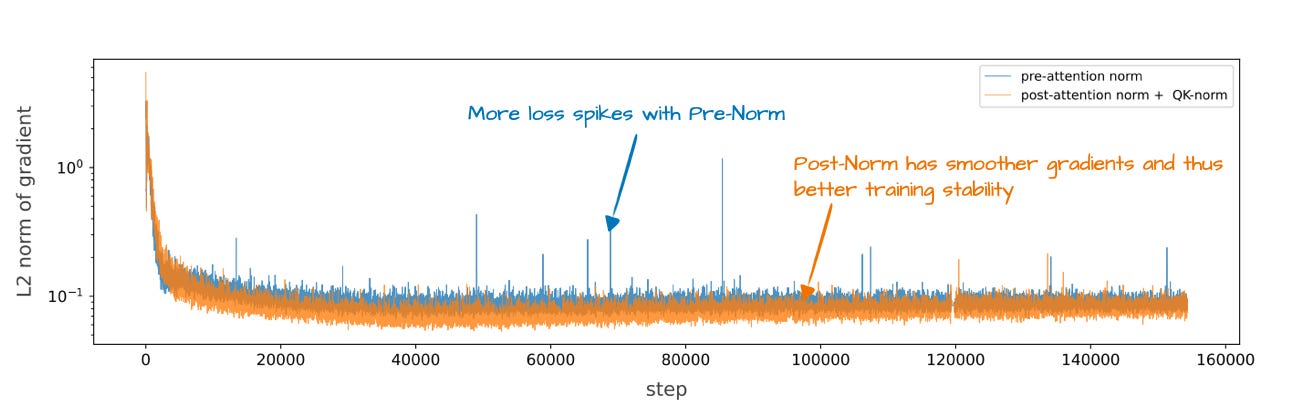
Figure 9 - Caption: Figure 9: A plot showing the training stability for Pre-Norm versus OLMo 2’s flavor of Post-Norm.
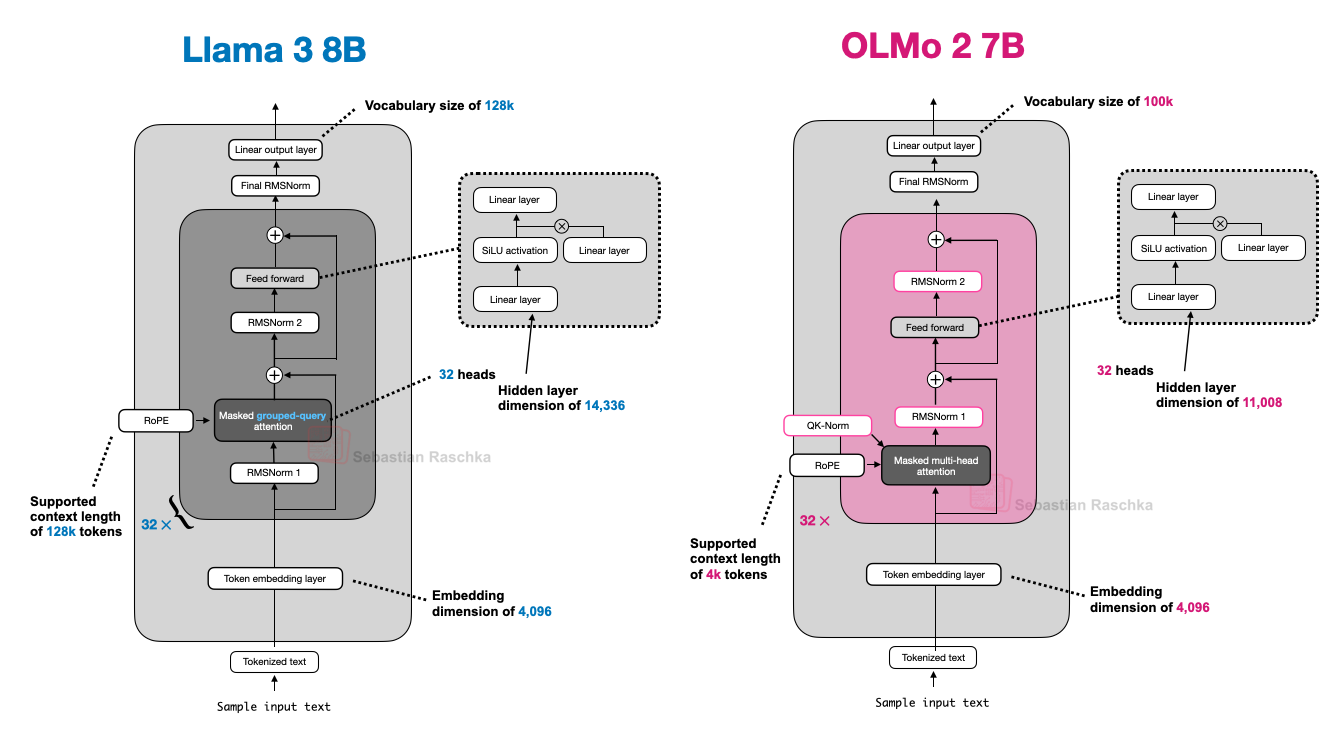
Figure 10 - Caption: Figure 10: An architecture comparison between Llama 3 and OLMo 2.
Full Text Content
Last updated: Dec 18, 2025
It has been seven years since the original GPT architecture was developed. At first glance, looking back at GPT-2 (2019) and forward to DeepSeek V3 and Llama 4 (2024-2025), one might be surprised at how structurally similar these models still are.
Sure, positional embeddings have evolved from absolute to rotational (RoPE), Multi-Head Attention has largely given way to Grouped-Query Attention, and the more efficient SwiGLU has replaced activation functions like GELU. But beneath these minor refinements, have we truly seen groundbreaking changes, or are we simply polishing the same architectural foundations?
Comparing LLMs to determine the key ingredients that contribute to their good (or not-so-good) performance is notoriously challenging: datasets, training techniques, and hyperparameters vary widely and are often not well documented.
However, I think that there is still a lot of value in examining the structural changes of the architectures themselves to see what LLM developers are up to in 2025.
Table of Contents
- DeepSeek V3/R1
- 1.1 Multi-Head Latent Attention (MLA)
- 1.2 Mixture-of-Experts (MoE)
- 1.3 DeepSeek Summary
- OLMo 2
- 2.1 Normalization Layer Placement
- 2.2 QK-Norm
- 2.3 OLMo 2 Summary
- Gemma 3
- 3.1 Sliding Window Attention
- 3.2 Normalization Layer Placement in Gemma 3
- 3.3 Gemma 3 Summary
- 3.4 Bonus: Gemma 3n
- Mistral Small 3.1
- Llama 4
- Qwen3
- 6.1 Qwen3 (Dense)
- 6.2 Qwen3 (MoE)
- SmolLM3
- 7.1 No Positional Embeddings (NoPE)
- Kimi K2 and Kimi K2 Thinking
- GPT-OSS
- 9.1 Width Versus Depth
- 9.2 Few Large Versus Many Small Experts
- 9.3 Attention Bias and Attention Sinks
- Grok 2.5
- GLM-4.5
- Qwen3-Next
- 12.1 Expert Size and Number
- 12.2 Gated DeltaNet + Gated Attention Hybrid
- 12.3 Multi-Token Prediction
- MiniMax-M2
- Kimi Linear
- Olmo 3 Thinking
- DeepSeek V3.2
- Mistral 3
- Nemotron 3
- Xiaomi MiMo-V2-Flash
[Full article text continues with detailed technical content about each architecture…]